


Snowflake data warehouse uses “virtual warehouses” (also called simply “warehouses”) as an abstraction to represent computing power. Snowflake warehouses allow you to execute data analytics queries in a performant, cost-effective manner using Snowflake’s proprietary SQL query engine. Similar to virtual machines in other data platforms, the warehouses in your Snowflake account have a fixed size that you or your data engineer must specify in advance.
The objective of choosing the size for a Snowflake warehouse is to provide a consistent query time for your data set. In other words, you choose the size of your Snowflake warehouses in order to produce predictable performance.
It’s reasonable to think about “nodes” (CPU nodes, or virtual machines) as a way of measuring the size of a warehouse, though Snowflake’s documentation doesn’t use the term nodes.
Instead, Snowflake uses the term “credits,” since credits are how you pay for Snowflake’s services. I’ll use the term nodes in this article, since it’s easier to understand than credits, but we should keep in mind that these are “virtual” nodes (not physical CPUs on a server somewhere).
How Many Nodes Are in a Snowflake Warehouse?
Let’s assume you have large query workloads that process gigabytes of data, meaning you’ll need a Snowflake warehouse other than the default of “X-Small” (extra small).
Each increase in warehouse size will double the number of nodes available to the query, starting with 1 node for an X-Small warehouse and scaling up to 512 nodes for a 6X-Large warehouse.
Since Snowflake warehouses double their processing power with each unit increase in size, the elapsed query time will be cut in half every time you scale up the warehouse size.
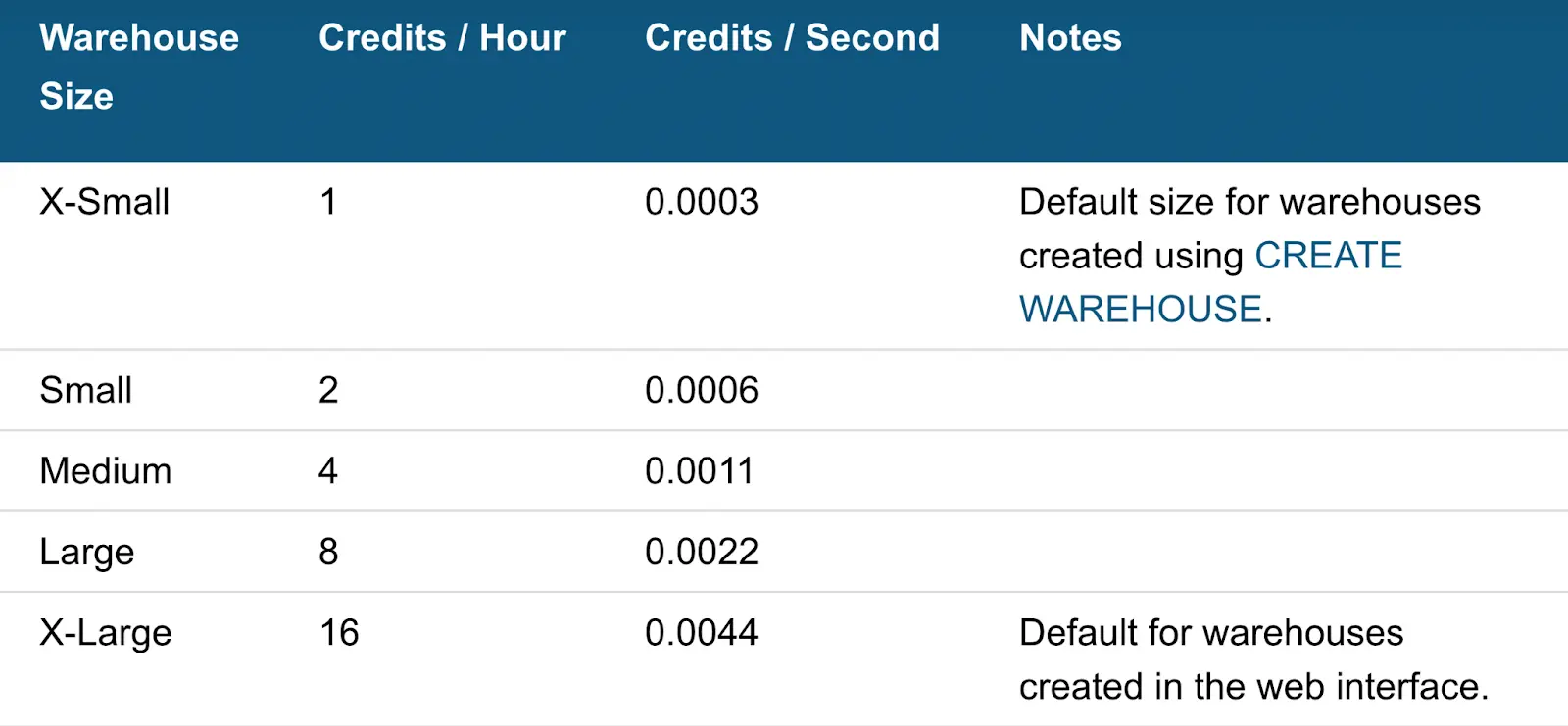
In other words, each increase in Snowflake’s resource allocations (via an increase in Snowflake warehouse size) includes more hardware CPU processing power. For example, a Medium warehouse has 4 nodes available in Snowflake, but a Large warehouse will have 8 nodes.
What effect do the available nodes have on the processing power available to Snowflake? When a query is executed on a warehouse, Snowflake may use as many CPU nodes as are available in parallel to execute the query.
The result is that a Large warehouse (8 credits / hour, or 8 nodes) will complete the same task twice as fast as a Medium warehouse (4 credits / hour, or 4 nodes). And the Medium warehouse will be 4x faster than the X-Small warehouse, which only has 1 node.
Do You Need Multiple Snowflake Warehouses?
So when might you have multiple warehouses, if just adding nodes to a single warehouse will make queries much, much faster? You’ll need to set up multiple Snowflake warehouses if you want to maintain predictable performance when running multiple queries at the same time.
“[Snowflake’s warehouses] are completely isolated from one another. Thus, there’s never a fight for resources or impact from the activities of another user.” –Snowflake Blog
Since your Snowflake warehouses are independent of each other, queries on one warehouse will not affect the other. The downside, of course, is that you can’t use the “nodes” (warehouse size) from one virtual warehouse to process a query from another Snowflake warehouse.
Be aware that you’ll need to take care to replicate your data between multiple warehouses so that your queries are always running on correct, up-to-date Snowflake databases. You may also want to explore multi-cluster warehouses in Snowflake, which allow you to scale up and scale down the number of “clusters” (warehouses) automatically as concurrency needs change.
On the other hand, if managing multiple Snowflake warehouses sounds like a headache, and you just want to build in-product analytics or other data apps, you should check out Propel Data Cloud’s easy-to-use GraphQL APIs. We take care of everything under the hood, from security to performance, to help you build data apps on top of Snowflake data in minutes, not months.
We would love you to stay in touch! Sign up for our free email newsletter, follow us over on our Twitter account @propeldatacloud, or join our new customer waiting list.




